Álgebra Linear Computacional
Aula 07: Normas de Vetores e Matrizes - Parte II
Exemplo 1
- Relação entre força de preensão (do aperto de mão) e força do braço para 147 pessoas que trabalham em empregos fisicamente extenuantes
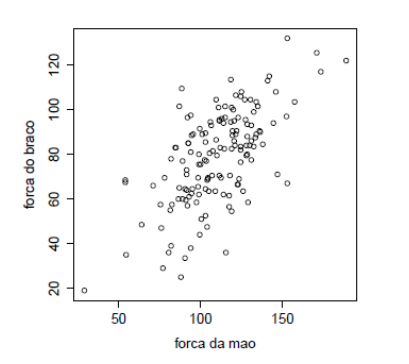
Matrizes de dados

Matriz de correlação
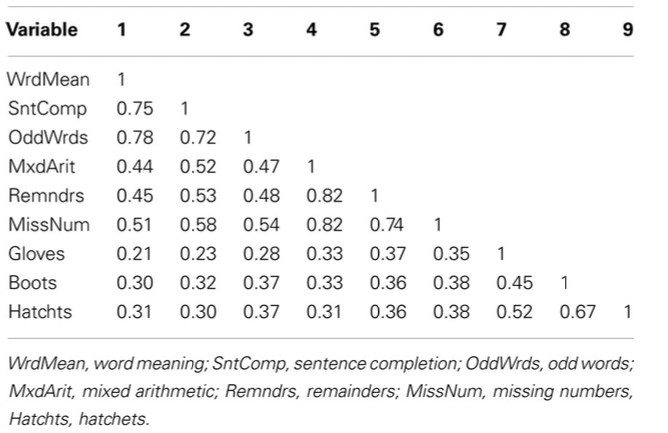
- Matriz simétrica e definida positiva
- Elemento \((i,j)\) mede o grau de associação linear entre um par de variáveis (diagonal 1, por quê?)
Desvio padrão
- Desvio padrão (\(\sigma\)) é o tamanho médio do desvio de um dado para a média
Pressão de 250 indivíduos
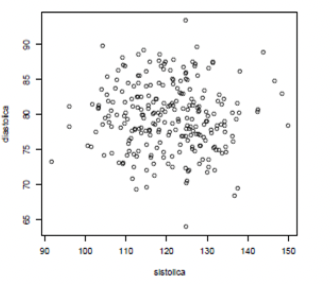
Amostra de \((y_{i1}, y_{i2})\), com \(i = 1,2,\ldots, 250\)
Médias para referência
- 250 instâncias do vetor aleatório: \(Y = (Y_1, Y_2)\)
- Vetor com os valores esperados de cada variável: \[\mathbb E(Y) = \mathbb E(Y_1,Y_2) = (\mathbb E(Y_1), \mathbb E(Y_2)) = (\mu_1, \mu_2) = \mu\]
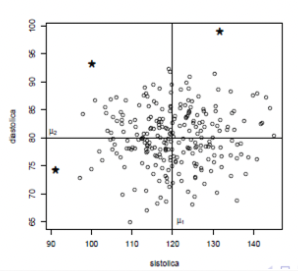
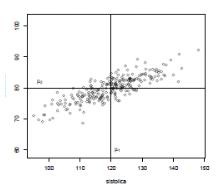
Quem está distante do esperado?
- Centro \(\mu = (\mu_1, \mu_2)\) é o perfil esperado ou típico
- Quem está longe do perfil típico? Quem é anômalo?
- Medida baseada na distância euclidiana \(d(y_1,y_2) = \sqrt{(y_1-120)^2+ (y_2-80)^2}\)
- é razoável?
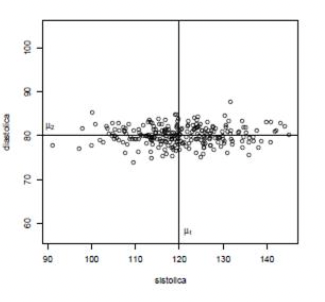
Exagerando um pouco
- E se o segundo atributo for assim? Fazendo o \(\text{aspect/ratio} = 1\).
- Centro \(\mu = (\mu_1, \mu_2)\) continua o mesmo
- Mas quem está distante do centro agora? Quem é anômalo?
Distantes são óbvios, não?
- Mas qual é a medida de distância que estamos usando sem ao mesmo perceber?
- Não é a distância euclidiana!
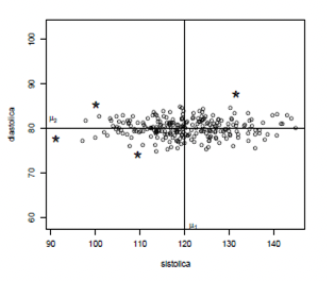
Pontos à igual distância
- Todos os pontos do círculo estão à igual distância do centro da nuvem de pontos
- Queremos os dois pontos em vermelho à igual distância ESTATÍSTICA do centro que os pontos em azul?
- NÃO! Pontos vermelhos estão ESTATISTICAMENTE muito mais distantes do centro \((\mu_1, \mu_2)\) do que os pontos azuis

Pontos vermelhos mais distantes
- Como fazer os pontos vermelhos mais distantes que os pontos azuis?
- Andar poucas unidades na direção norte-sul te leva pra fora da nuvem dos pontos (vira anomalia)
- Precisa andar MAIS unidades na direção leste-oeste para sair da nuvem de pontos
Pontos vermelhos mais distantes
- Então \(N\) unidades euclidianas na direção leste-oeste valem o MESMO que \(N/k\) na direção norte-sul (onde \(k>1\))
- Como achar esse \(k\)?
- Como equalizar as distâncias?
- Resposta: Medindo distâncias em unidades de DESVIOS PADRÕES
Distância Euclidiana
Qual o desvio padrão de cada variável?
- Centro \(\mathbb E(Y) = \mu = (\mu_1, \mu_2) = (120,80)\)
- \(DP_1 = \sigma_1 = ??\)
- \(DP_2 = \sigma_2 = ??\)
Qual o desvio padrão de cada variável?
- Centro \(\mathbb E(Y) = \mu = (\mu_1, \mu_2) = (120,80)\)
- \(DP_1 = \sigma_1 = 10\)
- \(DP_2 = \sigma_2 = 2\)
Distância medida em DP
- \((\mu_1,\mu_2) = (120,80)\) e \((\sigma_1, \sigma_2) = (10,2)\)
- AZUL: afastou-se do centro apenas ao longo do eixo 1 e afastou-se \(15\) unidades, ou \(1.5\sigma_1\)
- VERMELHO: afastou-se do centro apenas ao longo do eixo 2 e afastou-se \(15\) unidades ou \(7.5\sigma_2\)
- o ponto VERMELHO está muito mais distante do centro em termos de DPs
- Mas como fazer com pontos que afastam-se do centro não somente ao longo de um dos eixos?
Distância medida em DP
- \((\mu_1,\mu_2) = (120,80)\) e \((\sigma_1, \sigma_2) = (10,2)\)
- Andar \(n\sigma_1\) ao longo do eixo 1 é EQUIVALENTE a andar \(n\sigma_2\) no eixo 2
- Por exemplo, 20 unidades ao longo do eixo 1 (ou \(2\sigma_1\)) é ESTATISTICAMENTE EQUIVALENTE a 4 unidades ao (ou \(2\sigma_2\)) longo do eixo 2
![]()
Pontos a igual distância
- NESSA NOVA MÉTRICA, quais os pontos \((y_1, y_2)\) que estão a uma MESMA distância do centro \((\mu_1, \mu_2)\)?
- Tome uma distância fixa (por exemplo, 1)
- Eles formam uma ELIPSE centrada em \((\mu_1, \mu_2)\) e com eixos paralelos aos eixos coordenados
![]()
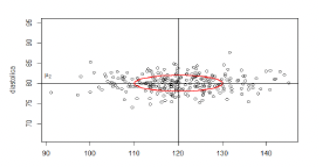
\[ d(y, \mu) = \sqrt{\left(\frac{y_1-120}{10}\right)^2 + \left(\frac{y_2-80}{2}\right)^2} =1 \]
Variando a distância
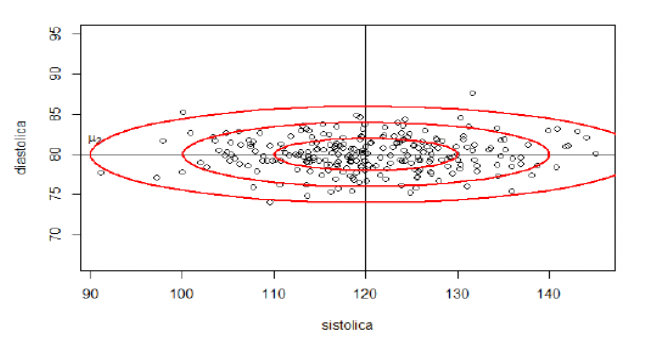
Pontos \((y_1, y_2)\) que estão a uma distância \(c\) igual a 1, 2, 3 do centro \((\mu_1, \mu_2)\)
Caso mais realista
- Variáveis são associadas, não são independentes
- Dizemos que são correlacionadas: redundância da informação
- O valor de uma variável dá informação sobre o valor da outra variável
- Pode-se predizer (com algum erro) uma variável em função da outra
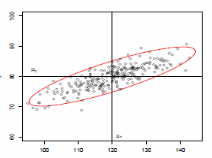
Distância elíptica e não circular
- Pelo mesmo raciocínio intuitivo que fizemos anteriormente, a ELIPSE abaixo tende a estar a igual distância do perfil esperado \(\mathbb E(Y) = \mu = (\mu_1,\mu_2)\)
- Pontos estatisticamente equidistantes de \(\mu\) NÃO estão mais numa elipse paralela aos eixos
- A elipse está inclinada seguindo a associação entre as variáveis
Forma quadrática
- Medida de distância é uma FORMA QUADRÁTICA \[ d^2(y,\mu) = (y-\mu)^\top \Sigma^{-1}(y-\mu)\]
- É a memsa expressão matricial de distância que usamos antes MAS…
- … a matriz não é mais DIAGONAL
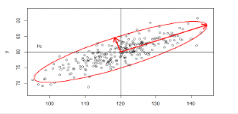
Relação entre \(\Sigma\) e a elipse
- distância é \[ d^2(y,\mu) = (y-\mu)^\top \Sigma^{-1}(y-\mu)\] onde \(\Sigma\) é uma matriz \(2\times 2\) simétrica dada por \[ \Sigma = \begin{bmatrix}\sigma_1^2 & \rho\sigma_1\sigma_2\\ \rho\sigma_1\sigma_2 & \sigma_2^2\end{bmatrix}\]
- Pontos equidistantes de \(\mu = (\mu_1, \mu_2)\) estão numa elipse
- Eixos da elipse: na direção dos AUTOVETORES da matriz \(\Sigma^{-1}\)
- O tamanho de cada eixo é proporcional à raiz do AUTOVALOR correspondente
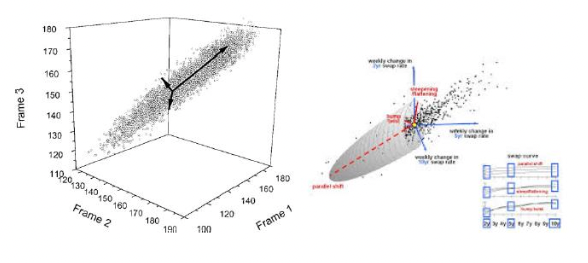
Caso 3D
Normas de matrizes
A norma de uma matriz é uma função \(\Vert \star\Vert\) do conjunto de todas as matrizes complexas (de todas as ordens finitas) para \(\mathbb R\) que satisfaz as seguintes propriedades
- \(\Vert A\Vert \le 0\) e \(\Vert A \Vert = 0 \Leftrightarrow A = 0\)
- \(\Vert \lambda A\Vert = \vert \lambda\vert \Vert A \Vert\) para todos escalar \(\lambda\)
- \(\Vert A + B \Vert \le \Vert A \Vert + \Vert B \Vert\) para matrizes do mesmo tamanho
- \(\Vert AB\Vert \le \Vert A \Vert \Vert B \Vert\) para todas as matriz compatíveis
