Álgebra Linear Computacional
Aula 09: PageRank

Uma grande inovação do final dos anos 90 é o surgimento das ferramentas de busca, começando com Alta Vista do DEC’s Western Research Lab e tendo como ápice o Google, fundado pelos doutorandos de Stanford Larry Page e Sergey Brin

Ideia original do Google
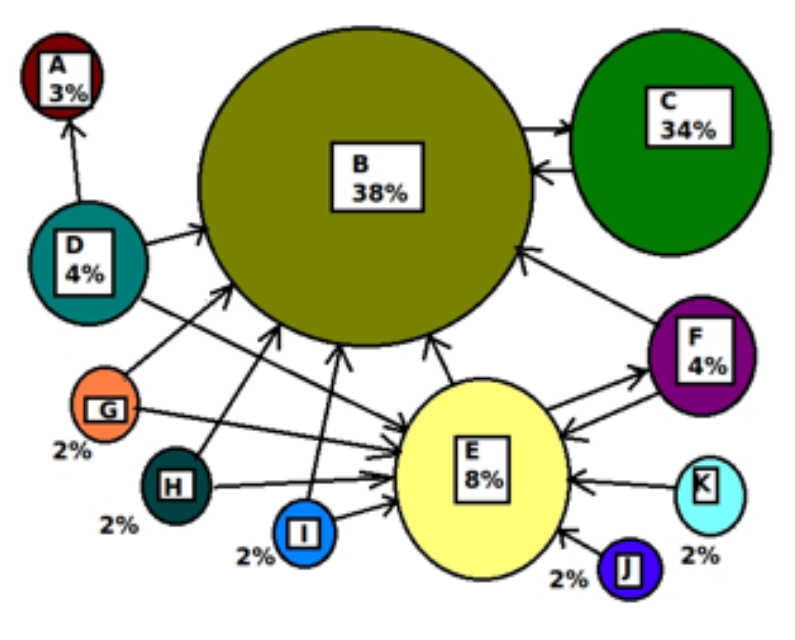
- Pagerank (importância) de uma página \(i\) é baseada nos links que recebe de outras páginas:
- Se \(i\) recebe links de páginas com pagerank alto, links contribuem bastante (recursão!)
- Se as páginas que tem link para \(i\), tem link para muitas páginas, contribuição é menor
Por que BrokenRank é broken?
Problema: o grafo sobre o qual o random surfer navega não é fortemente conectado 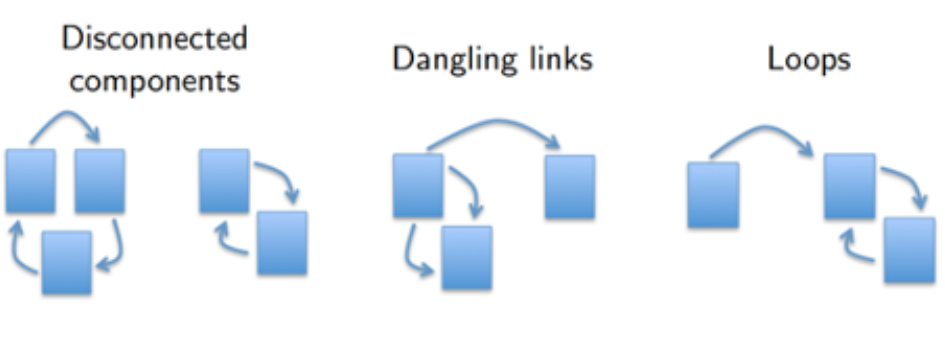
Note
Vetor p sempre existe, mas pode não ser único. Ou seja, o vetor BrokenRank \(p\) existe, mas é ambíguo.
Exemplo com BrokenRank
\[ A = LM^{-1} = \begin{bmatrix}0&0&1&0&0\\1&0&0&0&0\\0&1&0&0&0\\0&0&0&0&1\\0&0&0&1&0\end{bmatrix}\]
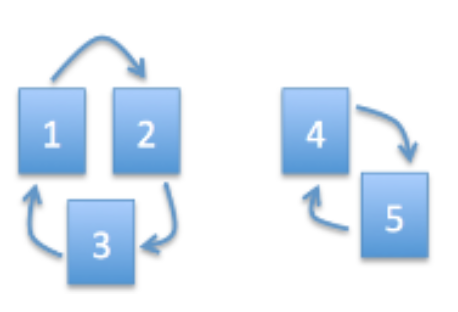
2 autovetores de \(A\) com \(\lambda=1\)
\[p = \begin{bmatrix}\frac{1}{3}\\\frac{1}{3}\\\frac{1}{3}\\0\\0\end{bmatrix} \text{ e } \begin{bmatrix}0\\0\\0\\\frac{1}{2}\\\frac{1}{2}\end{bmatrix}\]
Important
Estes rankings são totalmente opostos!
PageRank possui \(p\) único
Este modelo é um random surfer com random jumps
Agora existe um caminho de cada página para todas as outras páginas. Portanto, o vetor \(p\) é único (quando sujeito à restrição \(\sum_{i} p_i = 1\)).

Exemplo
Com \(d = 0.85, A= \frac{1-d}{n}E + d LM^{-1}\)
Exemplo
Com \(d = 0.85, A= \frac{1-d}{n}E + d LM^{-1}\)
\[\begin{align} &= \frac{0.15}{5}\begin{bmatrix}1 & 1 & 1 & 1 & 1\\1 & 1 & 1 & 1 & 1\\1 & 1 & 1 & 1 & 1\\1 & 1 & 1 & 1 & 1\\1 & 1 & 1 & 1 & 1\end{bmatrix} + 0.85\begin{bmatrix}0 & 0 & 1 & 0 & 0\\1 & 0 & 0 & 0 & 0\\0 & 1 & 0 & 0 & 0\\0 & 0 & 0 & 0 & 1\\0 & 0 & 0 & 1 & 0\end{bmatrix}\\ &= \begin{bmatrix}0.03 & 0.03 & 0.88 & 0.03 & 0.03\\0.88 & 0.03 & 0.03 & 0.03 & 0.03\\0.03 & 0.88 & 0.03 & 0.03 & 0.03\\0.03 & 0.03 & 0.03 & 0.03 & 0.88\\0.03 & 0.03 & 0.03 & 0.88 & 0.03\end{bmatrix} \end{align}\]
Agora possui apenas um autovetor
\[ p = \begin{bmatrix}0.2\\0.2\\0.2\\0.2\\0.2\end{bmatrix}\]
Método da potência (Exemplo)
Comece com qualquer distribuição (ex: uniforme) 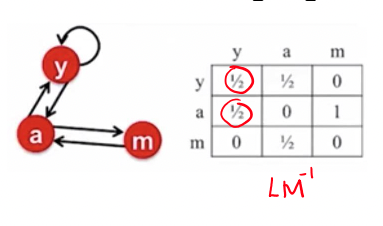
\[ p^{(0)} = \begin{bmatrix}1/3\\1/3\\1/3\end{bmatrix}\]
\[\begin{align} A &= \frac{1-d}{n}E + dLM^{-1}\\ &= \begin{bmatrix}0.05 & 0.05 & 0.05\\0.05 &0.05&0.05\\0.05&0.05&0.05\end{bmatrix} + \begin{bmatrix}0.425 & 0.425&0\\0.425&0&0.85\\0&0.425&0\end{bmatrix}\\ p^{(1)} &= \begin{bmatrix}0.475&0.475&0.05\\0.475&0.05&0.9\\0.05&0.475&0.05\end{bmatrix}\begin{bmatrix}1/3\\1/3\\1/3\end{bmatrix}\\ p^{(1)}&= \begin{bmatrix}0.333\\0.475\\0.192\end{bmatrix}\\ p^{(2)} &= \begin{bmatrix}0.475&0.475&0.05\\0.475&0.05&0.9\\0.05&0.475&0.05\end{bmatrix}\begin{bmatrix}0.333\\0.495\\0.192\end{bmatrix}\\ p^{(2)}&= \begin{bmatrix}0.394\\0.355\\0.252\end{bmatrix} \end{align}\]
Variantes / Extensões do PageRank

