Álgebra Linear Computacional
Aula 11: SVD e aproximação de matrizes
Exemplo de uma matriz tall-thin
Tall-thin matrix
Aprendendo sobre espaço latente

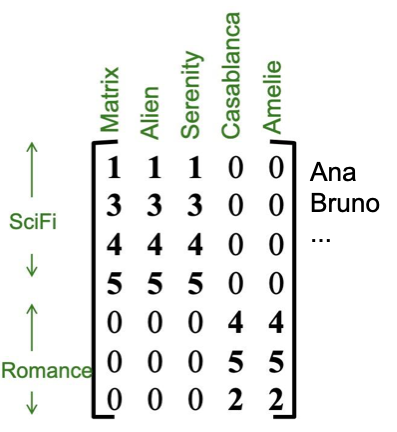
Usuário e conceito
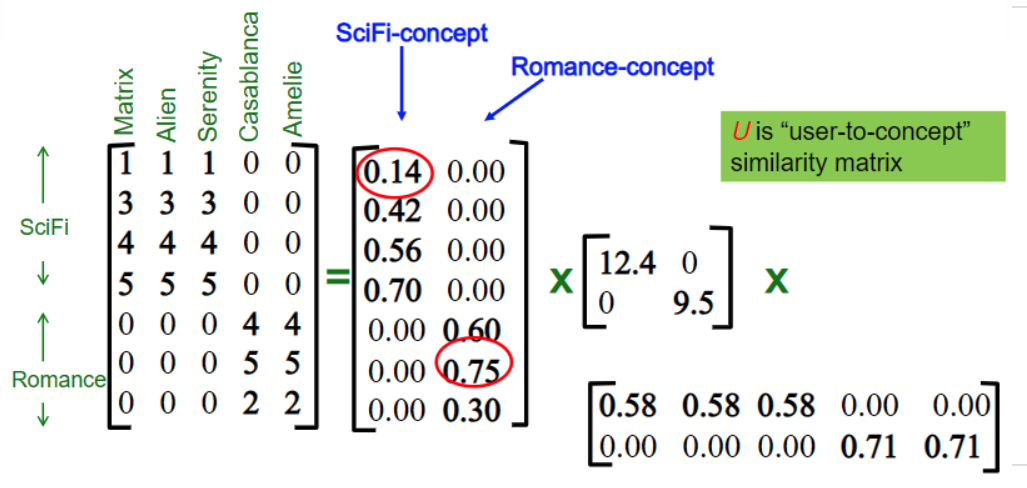
Filme e conceito
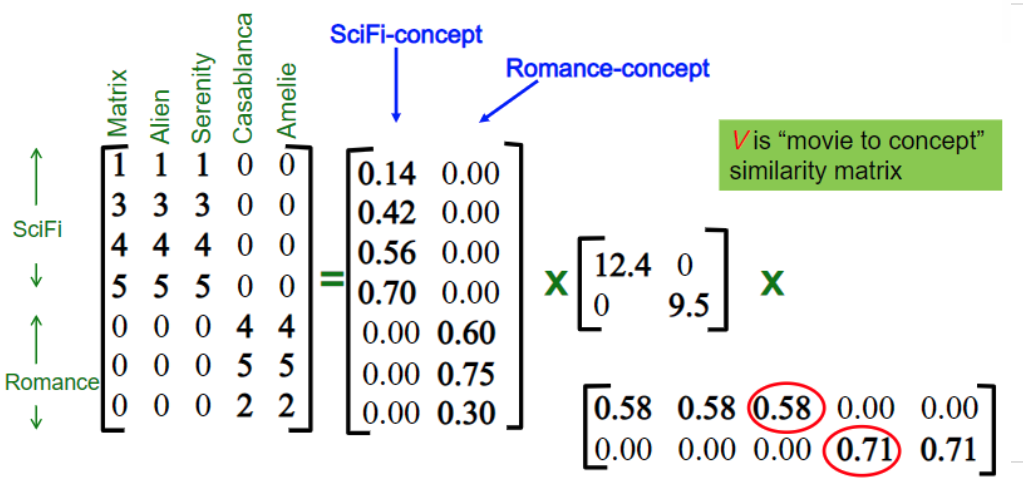
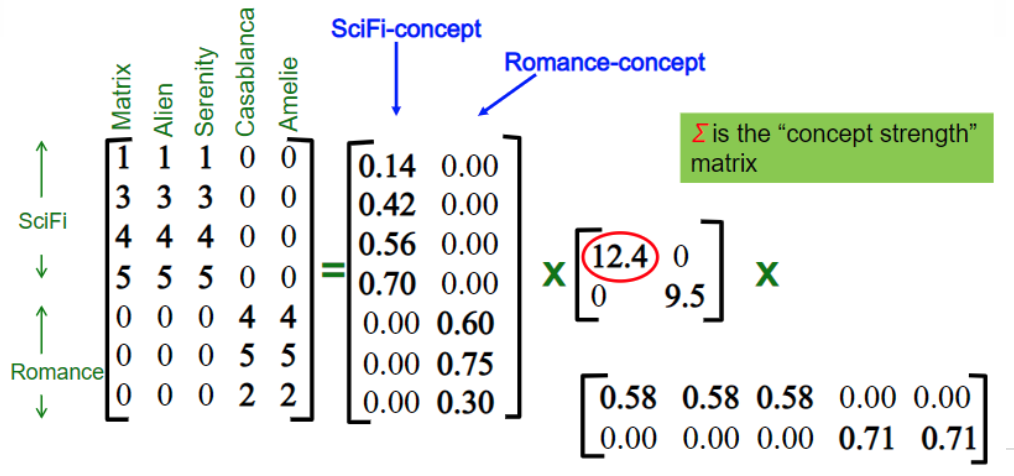
Peso de um conceito
Exemplo um pouco mais real
Note que existem usuários que vão assistir filmes de vários tipos (isso pode ser apenas ruído) 
Exemplo um pouco mais real

Um sistema de recomendação simples

Um sistema de recomendação simples
Como estamos supondo termos \(k=2\) perfis

Um sistema de recomendação simples
Ao realizar a multiplicação (após remover o menor valor singular)

Compressão de imagens
\(\approx 80\%\) da internet é imagem!

Compressão de imagens
Dimensões: (2560 x 1600) Número de bytes: 4.096.000 (imagem em tons de cinza - 1 byte por pixel)

Compressão de imagens
- A primeira aproximação seria \(A_1\)

Como ficaram as imagens?



Como ficaram os erros (visualmente)?



Até quando precisamos ir?

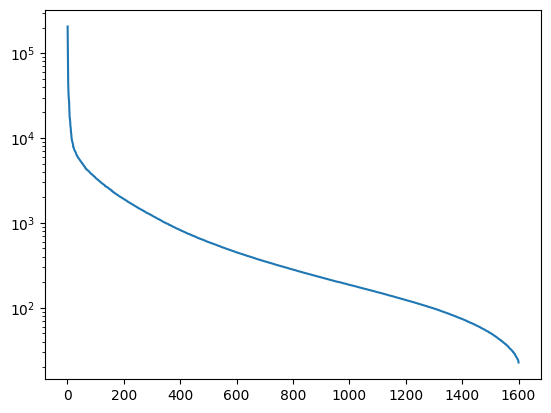
Até quando precisamos ir?
Regra do dedão: cortar de maneira a mantar entre 80-90% da “energia”
\[t = \frac{\sum_{i=1}^k \sigma_i^2}{\sum_{i=1}^n \sigma_i^2} \]

Energia
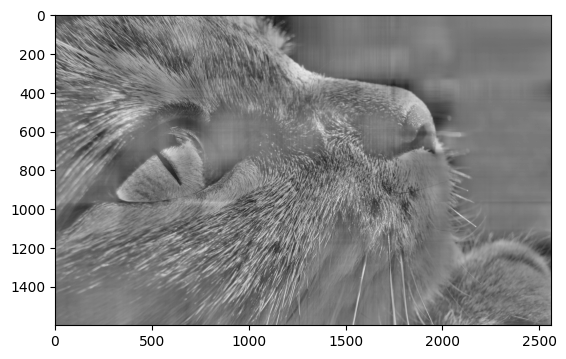
Resultados com \(A_{400}\)

\[RMSE(A_{400}) = 10969.759\]
Aproximação de matriz
Se \(B\) tem posto \(k\), então
\[ \Vert A - B \Vert \ge \Vert A - A_k \Vert\]
Norma de Frobenius:
\[ \Vert A \Vert_F = \sqrt{\vert a_{11}\vert^2 + \vert a_{12}\vert^2 +\ldots + \vert a_{mn}\vert^2}\]
Note
\(\Vert M \Vert_2\) é o maior valor singular \(\sigma_1\)
Relação entre Frobenius e norma-2: \[\Vert A\Vert_F \ge \Vert A\Vert_2\]
