Álgebra Linear Computacional
Aula 12: Análise de Componentes Principais
PCA
Técnica de análise de dados para redução de dimensionalidade
redução de dimensionalidade
PCA transforma um conjunto de variáveis possivelmente correlacionadas em um conjunto menor de variáveis chamadas componentes principais
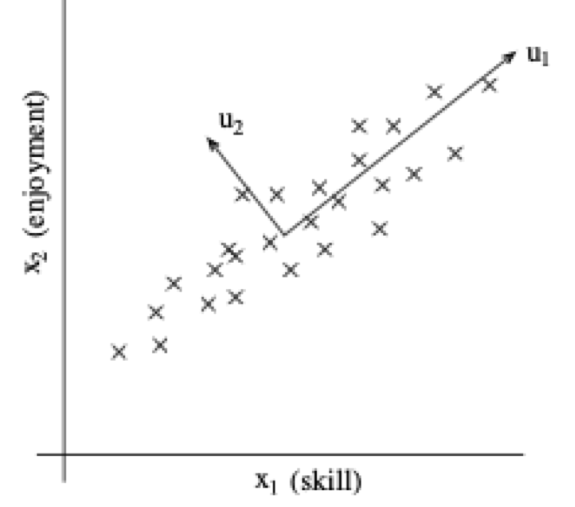
Exemplo: pilotos de helicóptero de controle remoto
- \(x_1^{(i)}\) é uma medida da habilidade do piloto \(i\)
- \(x_2^{(i)}\) é uma medida de quanto ele gosta de voar
- Suponha que apenas pilotos que treinam bastante, aqueles que realmente gostam de voar, se tornam bons pilotos
- Logo, \(x_1\) e \(x_2\) estão fortemente correlacionados.
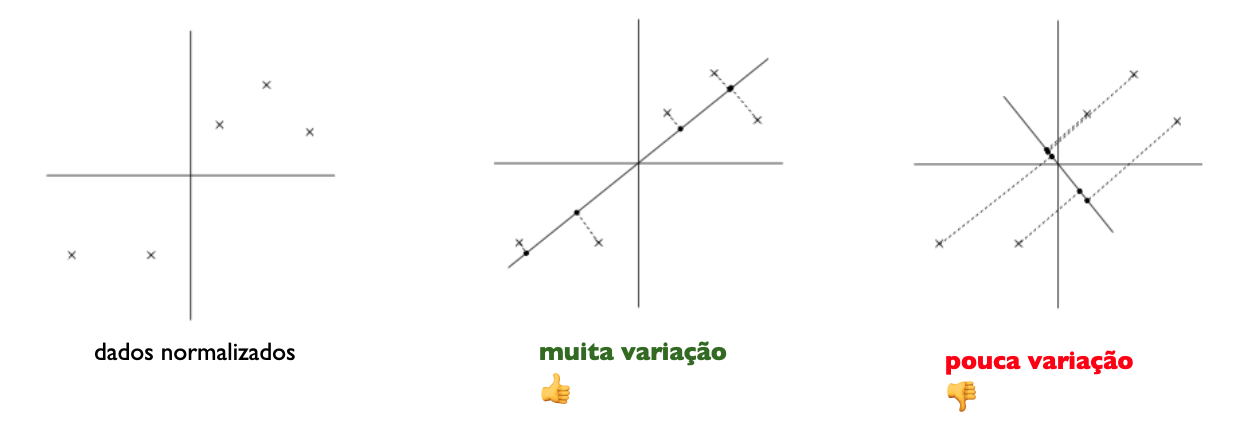
- Podemos conjecturar que os dados estão em um eixo “diagonal”, com apenas um pouco de ruído saindo do eixo.
![x_1 vs x_2]()
Important
Como determinar a direção de \(u_1\)?
Exemplos
Exemplos
Note
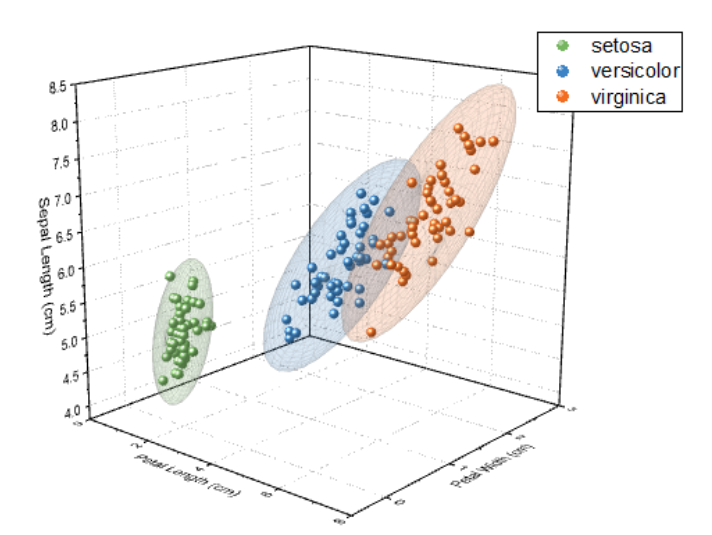
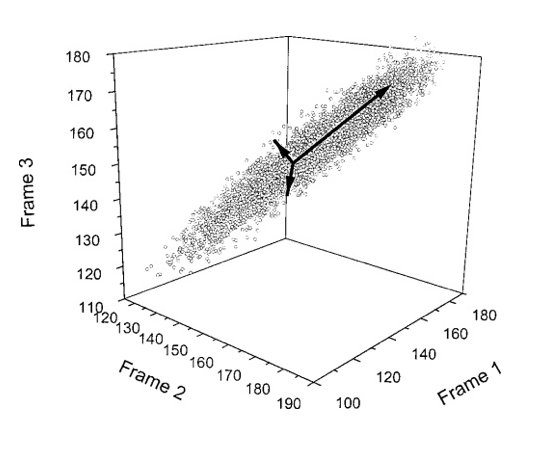
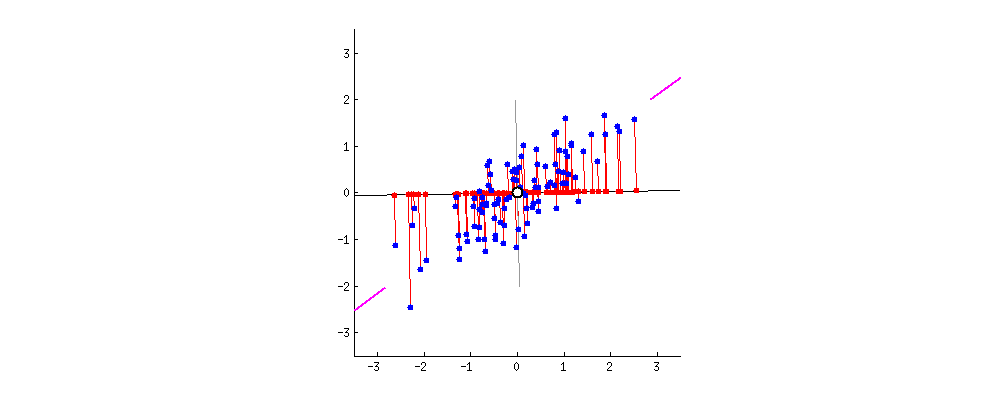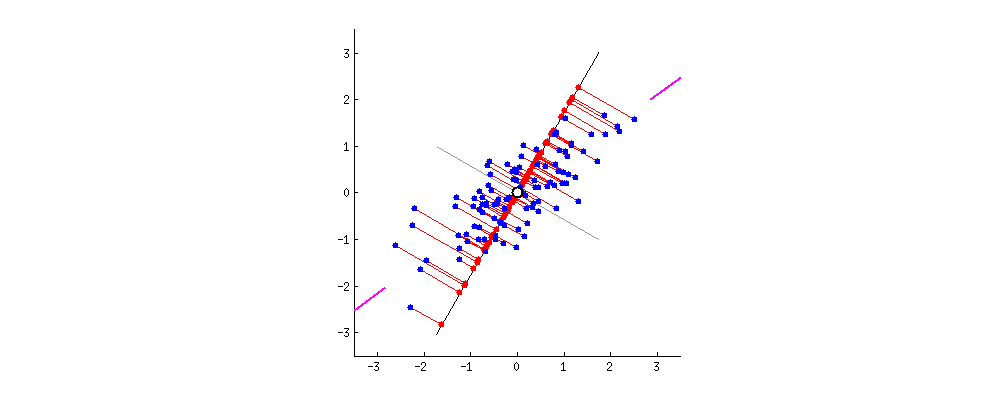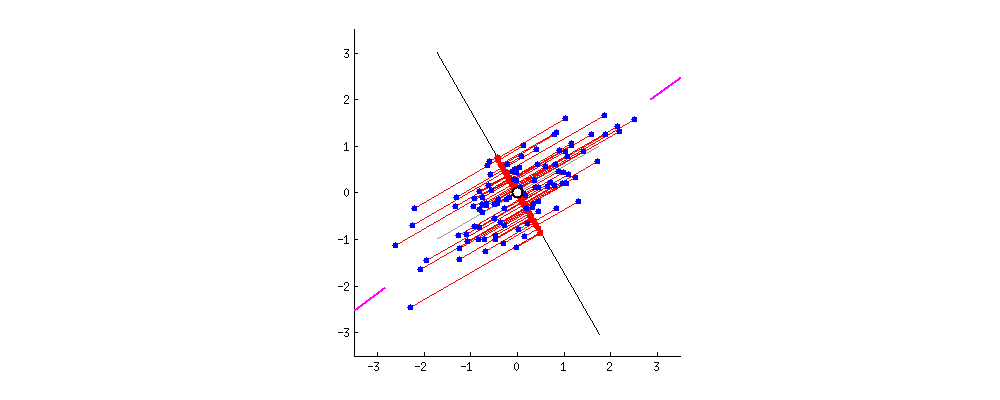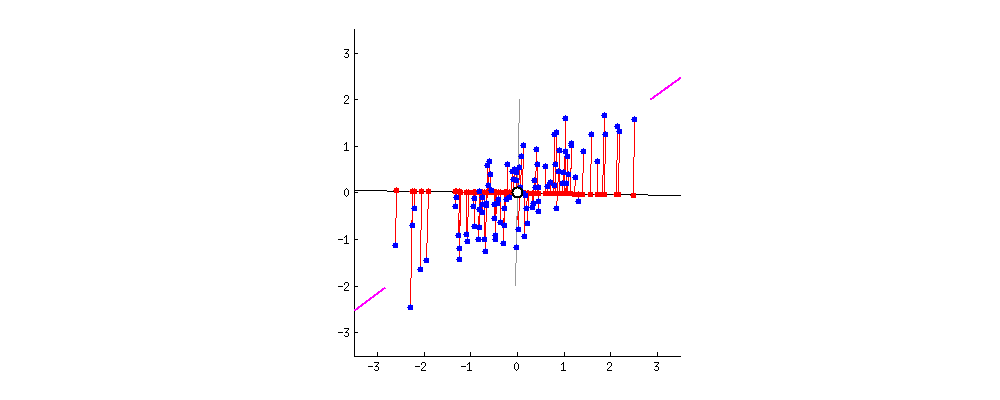
Nuvem de pontos
Projetando em eixos

Rodando os eixos com cuidado
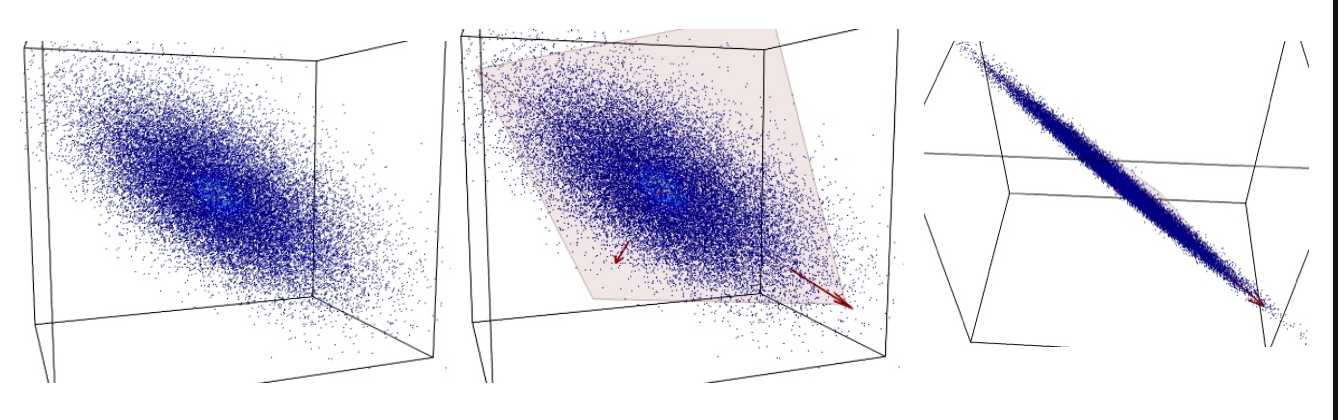
Note
De 3D para 2D
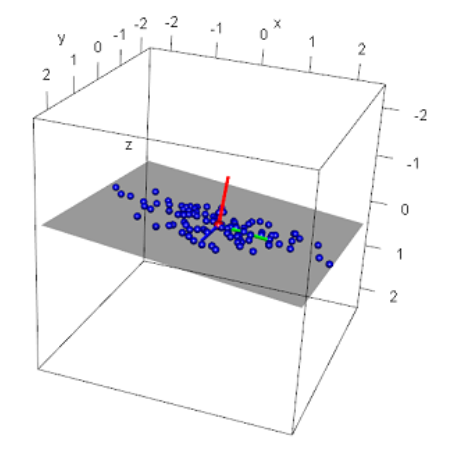
- Veja o novo sistema de coordenadas no gráfico
- Ele está “torto”com respeito ao sistema cartesiano da figura
- Neste NOVO sistema, podemos representar cada ponto de forma aproximada:
- Podemos usar as duas coordenadas dos eixos verde e azul e ignorar a coordenada do eixo vermelho
Note
- Nem sempre será possível obter uma boa aproximação.
- Será preciso checar quando isto será possível.
- Já veremos como fazer isto…
Centrando os pontos
\[ \begin{bmatrix} x_1\\ x_2\\ x_3 \end{bmatrix} = \begin{bmatrix} \mu_1\\ \mu_2\\ \mu_3 \end{bmatrix} + \left[ \begin{bmatrix} x_1\\ x_2\\ x_3 \end{bmatrix}- \begin{bmatrix} \mu_1\\ \mu_2\\ \mu_3 \end{bmatrix} \right] \]
\[ x = \mu + [x-\mu] = x+y\]
Subtraindo a média de cada coordenada-variável, temos um novo vetor \(y\) com média zero em cada coordenada.
A nuvem de pontos é deslocada rigidamente para a origem
Como calcular o eixo maior?
Problema: encontrar vetor unitário \(u\) que maximiza a variância dos dados projetados em \(u\).
Decomposição ortogonal
Dizer que o vetor \(x_W\) é o vetor mais próximo a \(x\) em \(W\) equivale a dizer que a diferença \(x - x_W\) é ortogonal a \(W\)
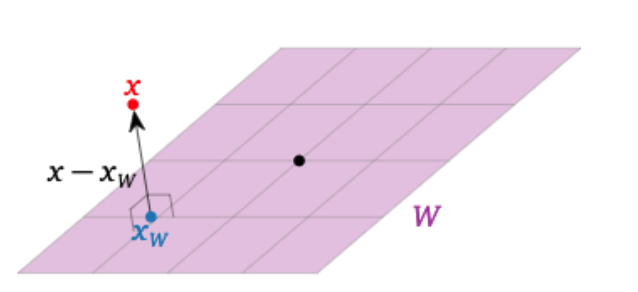
Se \(x_{W\perp} = x - x_W\), então \(x = x_W + x_{W^\perp}\), onde \(x_W\) está em \(W\) e \(x_{W^\perp}\) está em \(W^\perp\)
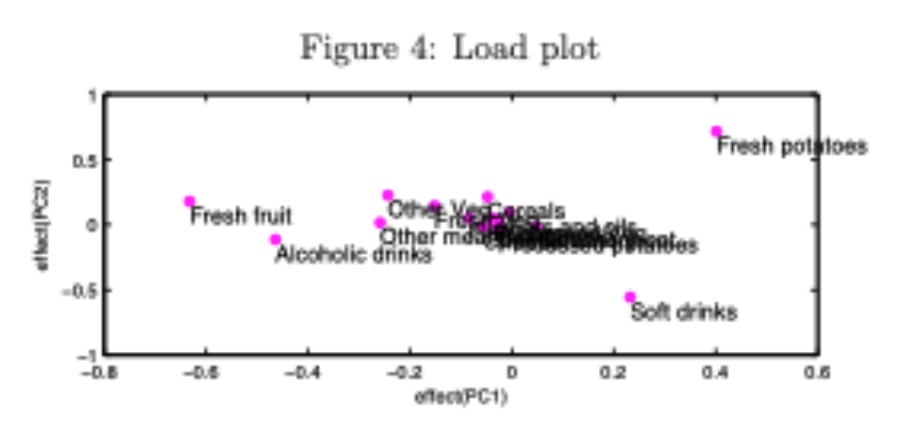
Exemplo de análise de dados multivariada
DEFRA (Department for Environment, Food and Rural Affairs) data: consumo (g/pessoa/semana), 17 tipos de comida, quatro países Reino Unido em 1997.
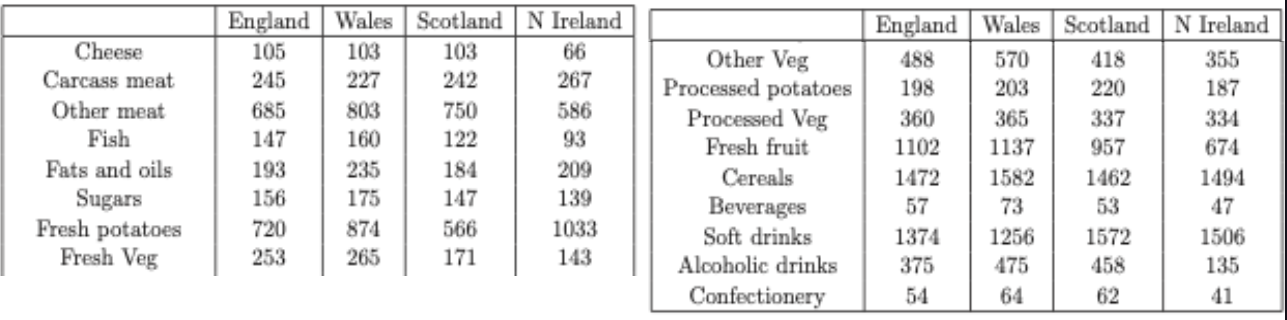
Como analisar estes dados? Existem correlações entre os países? Plotar todos de uma vez? Plotar variáveis 2 a 2?
PCA e a primeira componente principal (PC1)
O objetivo do PCA é identificar novo conjunto de eixos ortogonais de coord. a partir dos dados.
No primeiro passo, PCA encontra a primeira componente principal (PC1), direção que maximiza variância através das coords.
Após encontrar PC1, projetamos os dados neste novo eixo. Como? 
PCA e a segunda componente principal (PC1)
- PC2 é ortogonal a PC1
- Direção de maior variância dos dados, dentre direções ortogonais a PC1
- De novo, projetar coordenadas em PC2
![]()
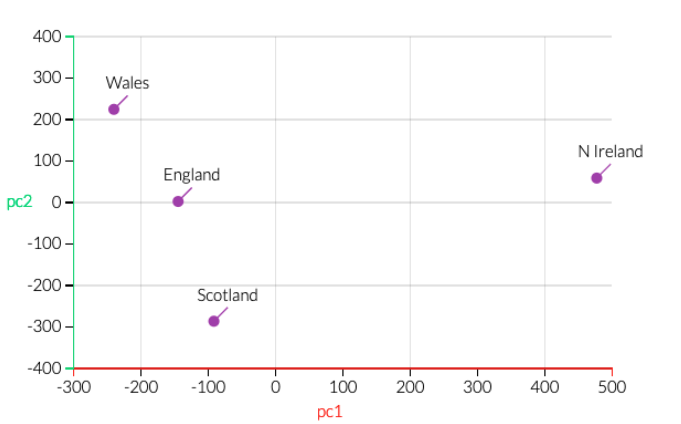
PCA vs variância explicada
- PCA também retorna info sobre contribuição de cada PC para a variância total dos dados: 67% por PC1, 97% por PC1+PC2
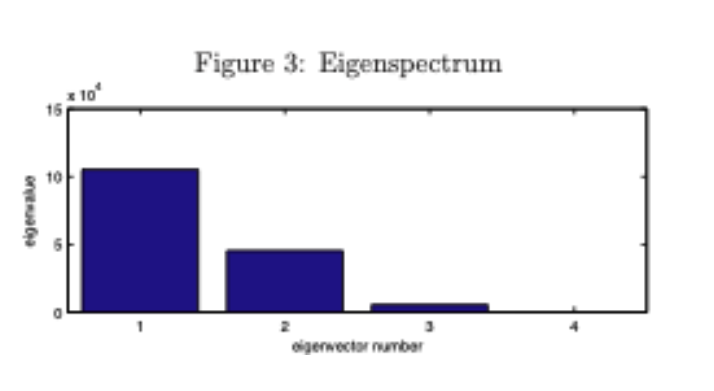
PCA: composição de cada PC
Também obtemos influência de cada variável original nos PCs