Álgebra Linear Computacional
Aula 14: Removendo Viés com PCA
Motivação
Muitas aplicações recebem como entrada um conjunto de palavras
Motivação
Muitas aplicações recebem como entrada um conjunto de palavras
Como representar as palavras?
Opção 1: usando “one hot” vectors Cada vetor tem o tamanho do vocabulário e apenas uma entrada não-nula, igual a 1

Word Embeddings
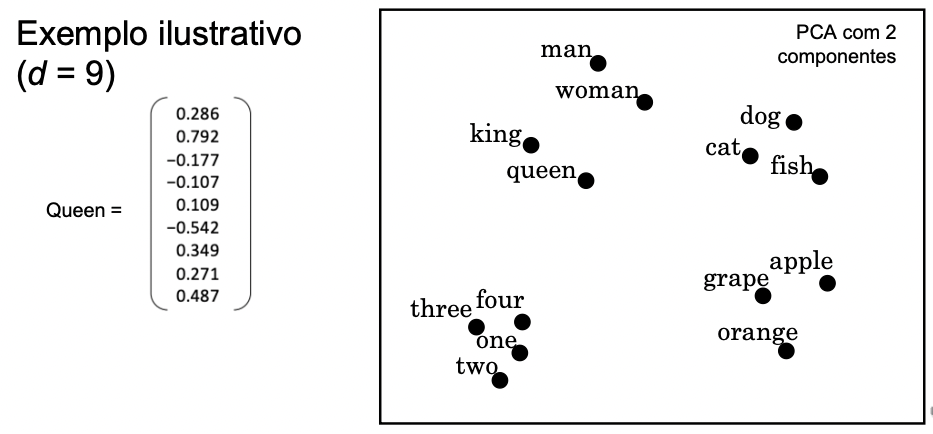
Analogias
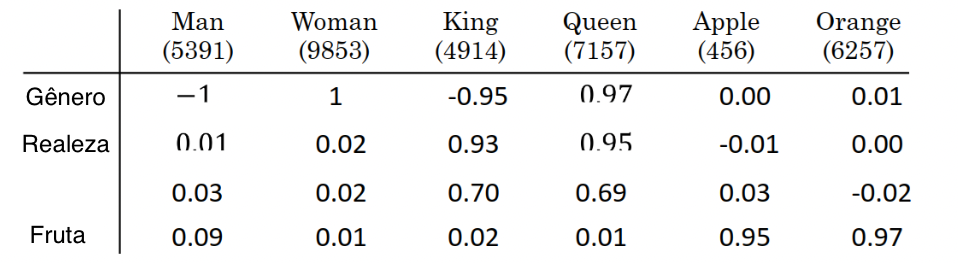 Homem está para mulher assim como Rei está para ? \(e_{man} \rightarrow e_{woman}\) assim como \(e_{king} \rightarrow e_{?}\)
Homem está para mulher assim como Rei está para ? \(e_{man} \rightarrow e_{woman}\) assim como \(e_{king} \rightarrow e_{?}\)
Como usar os embeddings para resolver essa questão?
\(e_{man} - e_{woman} \approxeq e_{king} - e_{?}\)
\(e_{man} - e_{woman} = \begin{bmatrix}-2\\ -0.01\\0.01\\ 0.08\end{bmatrix}\)
\(e_{?} \approxeq e_{king} - (e_{man} -e_{woman}) = \begin{bmatrix}-0.95\\ 0.93\\0.70\\ 0.02\end{bmatrix} - \begin{bmatrix}-2\\ -0.01\\0.01\\ 0.08\end{bmatrix}\)
\(e_{?} = \begin{bmatrix}1.05\\0.94\\0.69\\-0.06\end{bmatrix}\)
Analogias
\(e_{?} \approxeq e_{king} - (e_{man} -e_{woman})\)
Encontre a palavra \(w\colon \text{arg}\max_w sim(e_w, e_{king} - e_{man} + e_{woman})\)
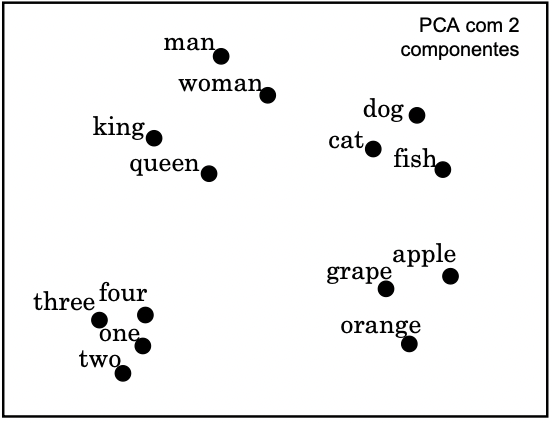
Exemplos semânticos
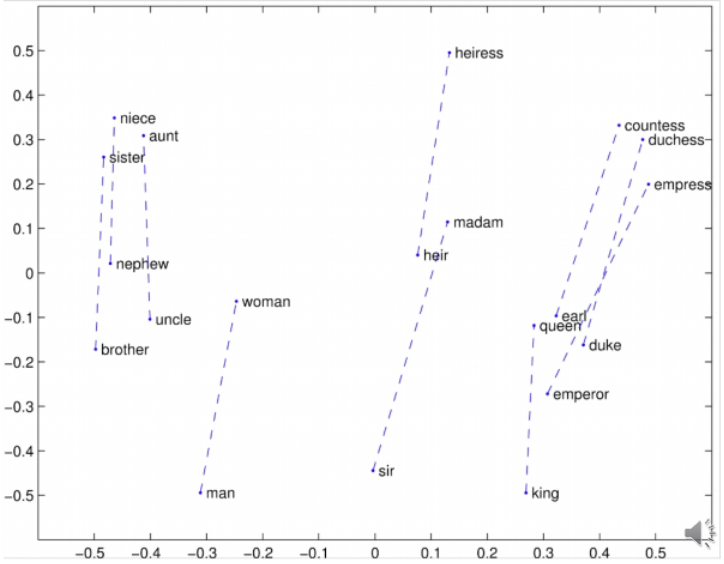
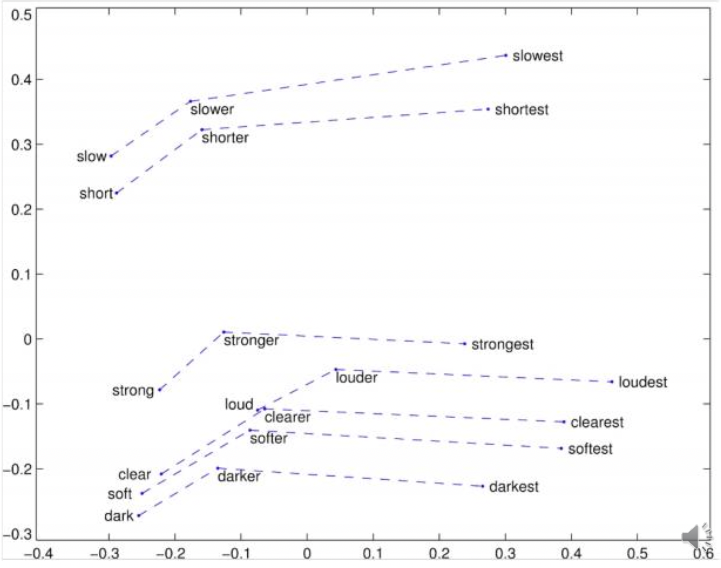
Exemplos sintáticos
Viés em word embeddings
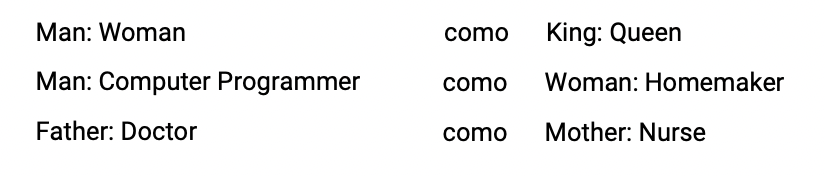
- Word embeddings podem refletir viéses de gênero, etnia, idade e orientação sexual presentes no texto usado para treiná-los
- Note que algoritmos de ML influenciam admissões em faculdades, matching de candidatos a empregos, empréstimos, guidelines usados para sentenças de prisão
Viés em word embeddings
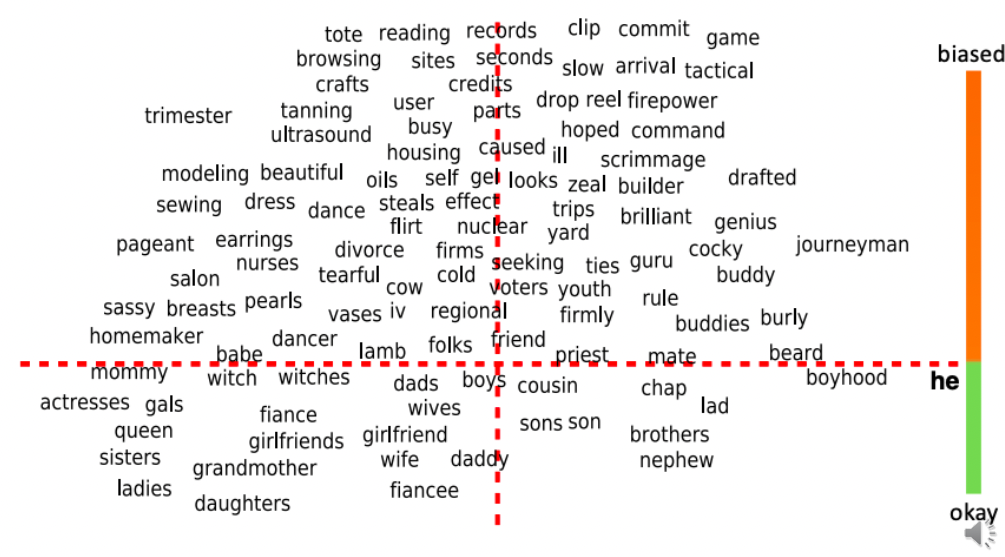
Removendo viés em word embedding
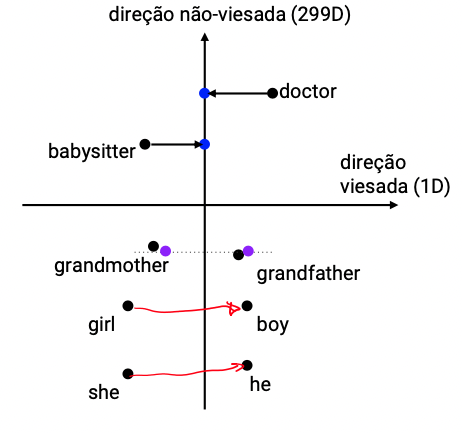
- Identifique a direção do viés usando palavras definicionais:
\(\longleftarrow \text{ média }\begin{cases}e_{he}-e_{she}\\e_{male} - e_{female}\\ \ldots\end{cases}\)
- Neutralize: para cada palavra neutra de gênero projete na direção não-viesada para se livrar do viés
- Equalize os pares de palavras definicionais para que palavras neutras tenham mesma distância dos pares
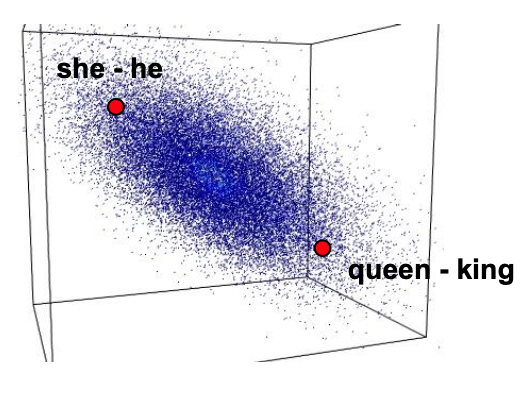
Uma nuvem de pontos
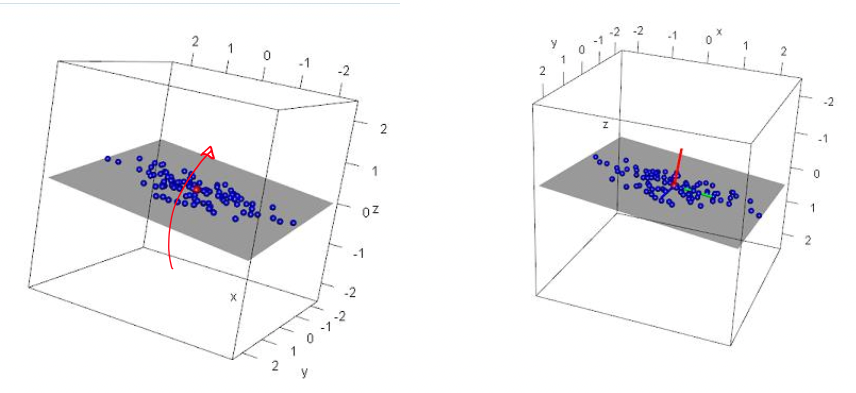
Rodando eixos com cuidado
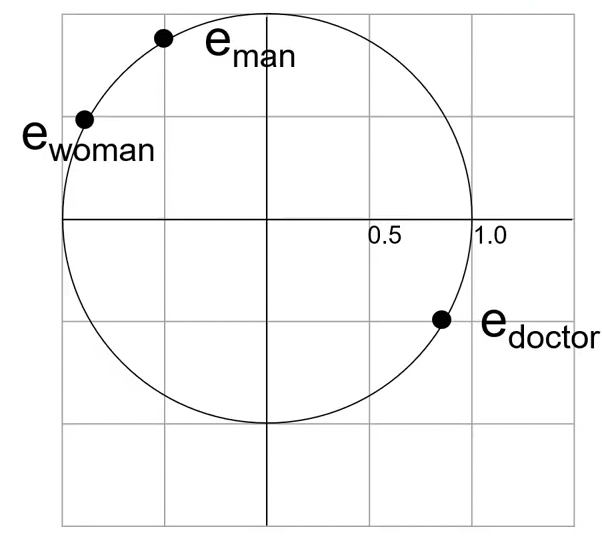
Neutralização (exemplo)
\(e_{man} =(-0.50,0.87)\)
\(e_{woman}=(-0.87,0.50)\)
\(e_{doctor} = (0.87,-0.50)\)
Neutralize \(e_{doctor}\)
\(g = e_{man} - e_{woman}\)
\(g = (0.37, 0.37)\)
Queremos que ele seja unitário: \[ g = \frac{g}{\Vert g\Vert}_2 = (0.71, 0.71)\]
\[\begin{align} e_B &= (e_{doctor}\cdot g)g\\ &= (0.87 \times 0.71 - 0.50 \times 0.71)g\\ &= 0.26(0.71, 0.71)\\ &= (0.18, 0.18) \end{align}\]
\[\begin{align} e_{doctor} &= e_{doctor} - e_B \\ &= (0.87, -0.50) - (0.18, 0.18) \\ &= (0.69, -0.69) \end{align}\]
\(e_{doctor} = \frac{e_{doctor}}{\Vert e_{doctor}\Vert_2} = (0.71, -0.71)\)
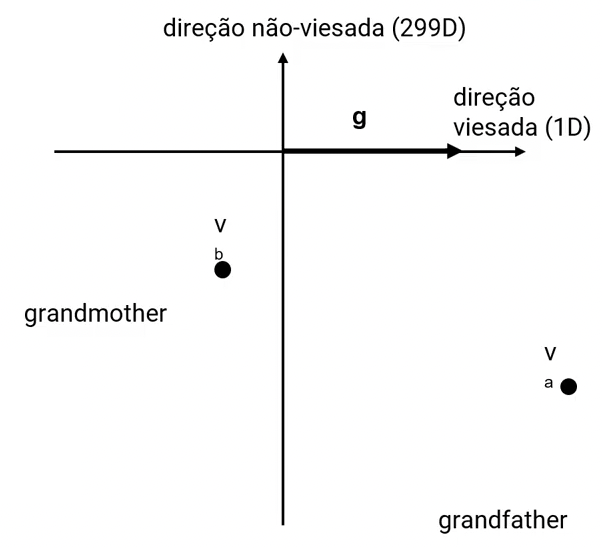
Passo 3: equalização
Um par definicional \((v_a,v_b)\) deve ter a mesma distância do plano não-viesado:
- Calcula média \(\mu = (va+vb)/2\)
- Remove viés \(y = \mu - \mu B\)
- Calcula componente viés \(z = \sqrt{1-\Vert y\Vert^2}\) de forma que \(\Vert y-zg\Vert = 1\)
- Adiciona viés \(z\) e \(-z\) para obter \(v_a = y + zg\) e \(v_b = y - zg\) embeddings neutralizados
Resumo
Word embeddings são representações densas de palavras usadas em tarefas de ML
- Embeddings podem conter viéses do conjunto de treinamento
- Vimos uma maneira de remover viés usando PCA
- Neutralizando palavras “neutras”
- Equalizando palavras definicionais
