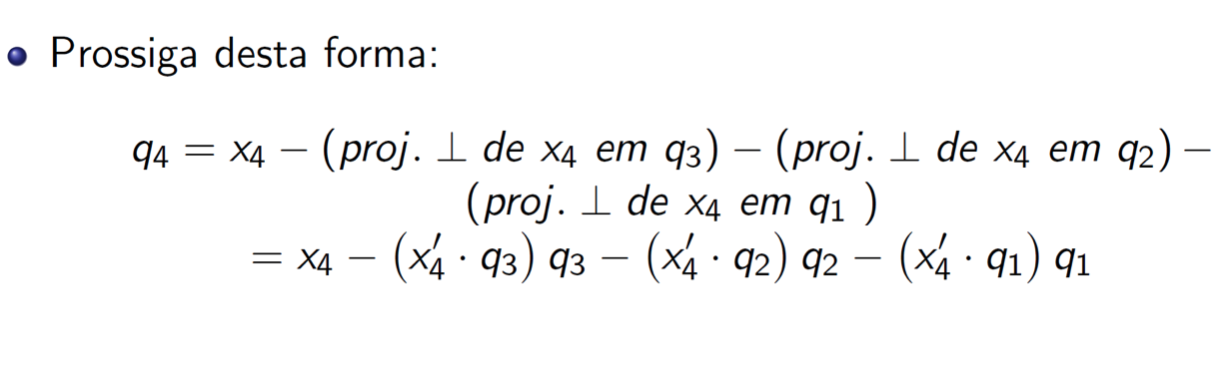Álgebra Linear Computacional
Aula 17: Coeficiente de Determinação / Resolução do problema de Mínimos Quadrados
Créditos
Os slides desse curso são fortemente baseados no curso do Fabrício Murai e do Erickson Nascimento
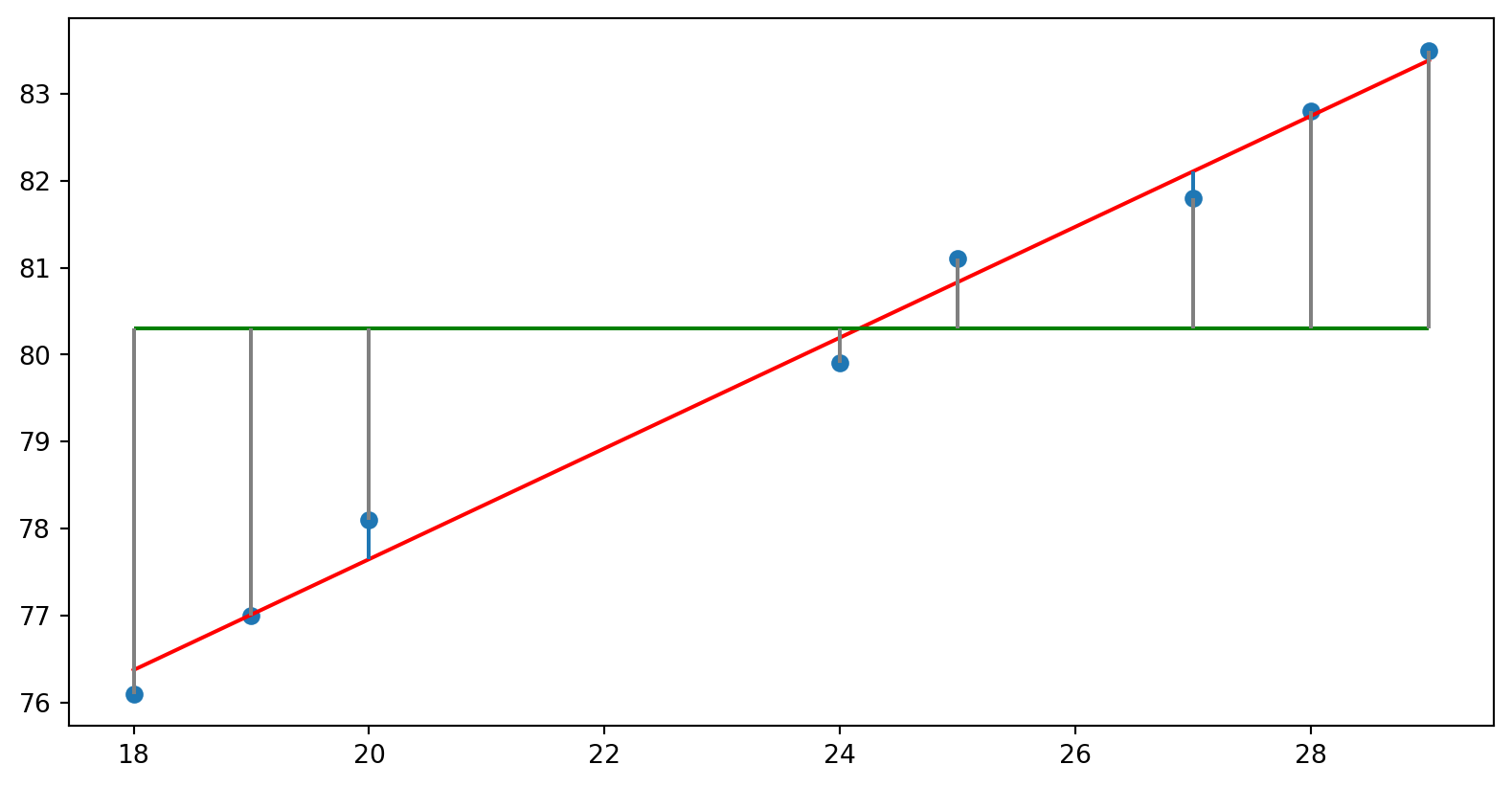
Considerações sobre o coeficiente de determinação
- Como avaliar se o modelo é bom?
- Em geral, quando o vetor de resíduos for “pequeno”, temos um bom ajuste \[
\Vert r \Vert^2 = \Vert Y - Y^2\Vert = \sum_{i=1}^n \left(y_i - \hat{y}\right )^2
\]
Mínimos quadrados
\[ x^* = \text{arg}\min_x \Vert Ax -b \Vert^2 \]
Tendo como equações normais
\[A^\top A x = A^\top b\]
ou
\[\begin{align}
(A^\top A)^{-1}A^\top A x &= (A^\top A)^{-1}A^\top b \\
x &= (A^\top A)^{-1}A^\top b
\end{align}\]
Exercício
Calcule a pseudoinversa da matrix \(A = \begin{bmatrix}1 & 2 \\ 1 & 2\end{bmatrix}\)
\[ A^\top A = \begin{bmatrix}1 & 1 \\ 2 & 2\end{bmatrix}\begin{bmatrix}1&2\\ 1&2\end{bmatrix} = \begin{bmatrix}2&4\\ 4&8\end{bmatrix}\]
Polinômio característico: \[(2- \lambda)(8 - \lambda) -16 = 0\] \[16 - 2\lambda - 8\lambda +\lambda^2 -16 = 0\]
\[ \lambda^2 - 10\lambda = 0\]
\[\lambda = 10 \text{ e } \lambda = 0\]
Calculando autovetor 1:
\[AX_1 = \lambda_1 X_1\]
\[\begin{bmatrix}2&4\\ 4 & 8\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix} = \begin{bmatrix}10x_1\\10x_2\end{bmatrix}\]
\[\begin{bmatrix}2x_1+4x_2\\ 4x_1 + 8x_2\end{bmatrix} = \begin{bmatrix}10x_1\\10x_2\end{bmatrix}\]
\[\begin{bmatrix}-8x_1+4x_2\\ 4x_1 - 2x_2\end{bmatrix} = \begin{bmatrix}0\\0\end{bmatrix}\]
\[-8x_1 = -4x_2 \Rightarrow x_1=\frac{1}{2}x_2\]
Normalizando o vetor \(X_1 = \begin{bmatrix}-\frac{1}{2}& -1\end{bmatrix}^\top\), temos \(X_1 = \begin{bmatrix}-0.4472136&-0.89442719 \end{bmatrix}^\top\)
Calculando autovetor 2 \[AX_2 = \lambda_1 X_2\]
\[\begin{bmatrix}2&4\\ 4 & 8\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix} = \begin{bmatrix}0\\0\end{bmatrix}\]
\[\begin{bmatrix}2x_1+4x_2\\ 4x_1 + 8x_2\end{bmatrix} = \begin{bmatrix}0\\0\end{bmatrix}\]
\[2x_1 = -4x_2 \Rightarrow x_1=-2x_2\]
Normalizando o vetor \(X_2 = \begin{bmatrix}-2&1\end{bmatrix}^\top\), temos \(X_2 = \begin{bmatrix}-0.89442719& 0.4472136 \end{bmatrix}^\top\)
Sendo assim, temos a decomposição SVD de \(A\) como
\[A = U\Sigma V^\top\]
com \[V^\top = \begin{bmatrix}-0.89442719& -0.4472136\\ 0.4472136& - 0.89442719\end{bmatrix}\]
\[\Sigma = \begin{bmatrix}0 & 0 \\ 0 & \sqrt{10} \end{bmatrix}\]
\[U = AV\Sigma^{-1} = \begin{bmatrix}1 & 2 \\ 1 & 2\end{bmatrix}\begin{bmatrix}-0.89442719 & -0.4472136 \\ 0.4472136& - 0.89442719 \end{bmatrix}\begin{bmatrix}0 & 0 \\ 0 & \frac{1}{\sqrt{10}} \end{bmatrix}\]
continua…. (ir para o Jupyter)
Decomposição QR
E se as colunas de \(A\) forem linearmente independentes?
Não precisamos de pseudoinversa!
Podemos procurar por matrizes fáceis de serem invertidas
- Ex: matrizes triangulares e ortogonais
Decomposição QR
Se tivermos a decomposição \(A = QR\), com \(Q^\top Q = I\) e \(R\) inversível, já sabemos como usá-la para obter os coeficientes \(\hat{\beta}_i\) em uma regressão.
Mas como obter \(A = QR\)?
Existe mais de uma maneira de obter
Vamos conhecer um algoritmo baseado na ortogonalização de Gram-Schmidt
O objetivo agora é transformar \(A\) em \(Q\), onde cada coluna \(q_i\) será ortonormal, ou seja, faremos \(q_i = \frac{A_i}{\Vert A_i\Vert}\)
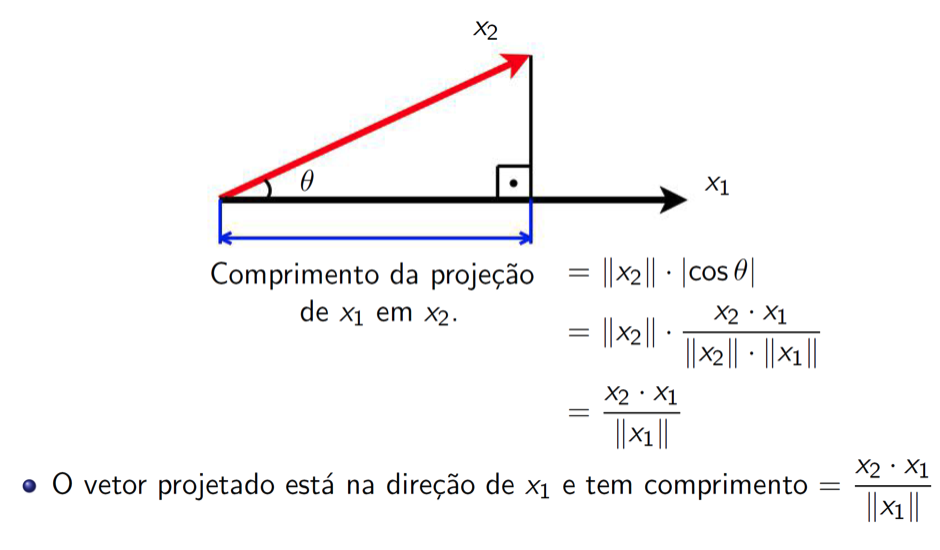
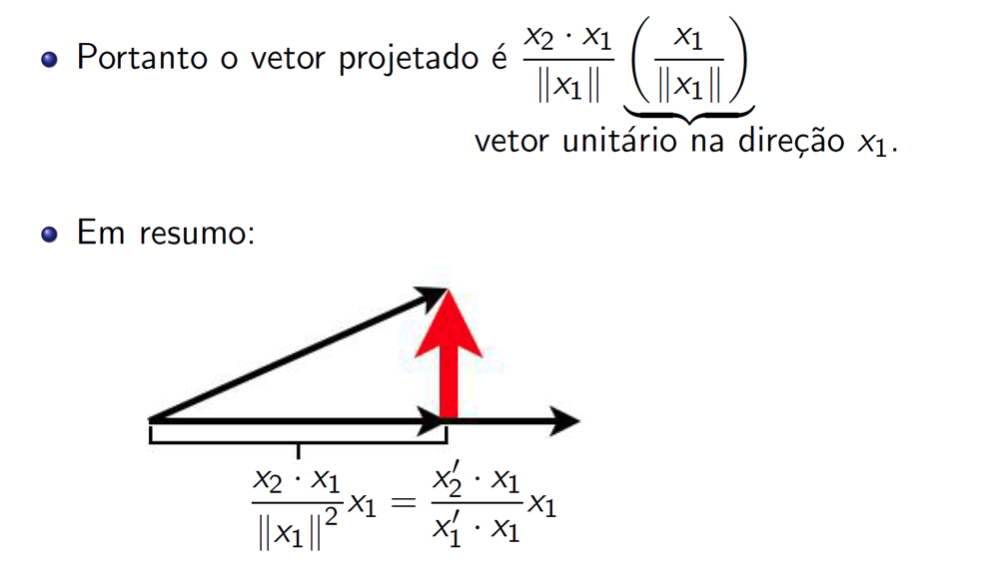
Projeção ortogonal
![]()
Projeção ortogonal
![]()
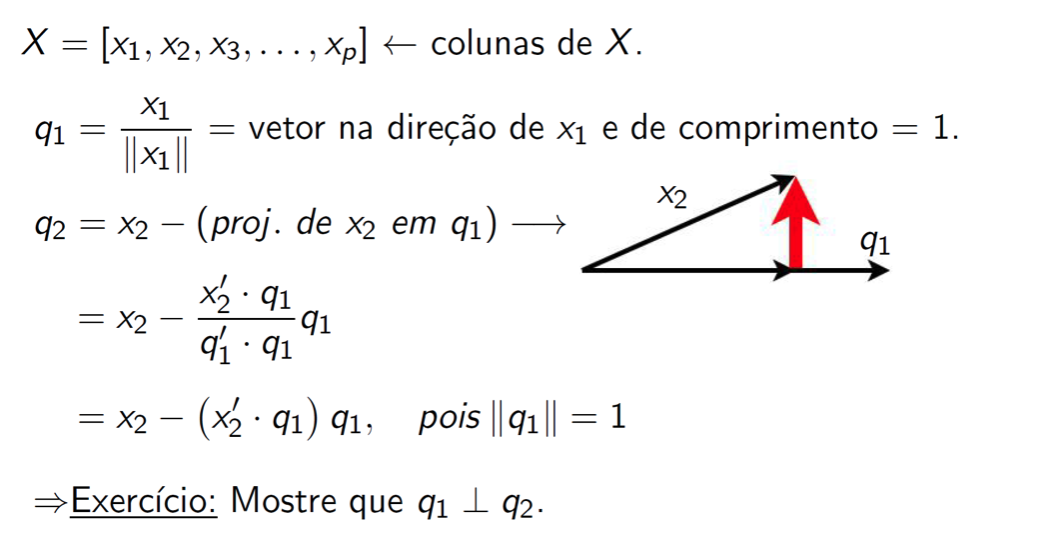
Gram-Schimidt
![]()
Gram-Schimidt
![]()
Gram-Schimidt
![]()
Como encontrar a matriz R?
\[ A = QR\]
\[Q^\top A = Q^\top Q R\]
\[R = Q^\top A\]